WPS 文档之一个空格引发的悬案

一个奇葩的空格
今天谷月老师在知乎上看到一个 奇怪的问题:
请问复制到WPS的文字里面有不能删除的空格,删了前面的文字也会一起删除,怎么办?

我一开始以为是这份文档设置了字符间距,在“字体”对话框的“字符间距”选项卡里改改字符间距就行了,多简单的事。
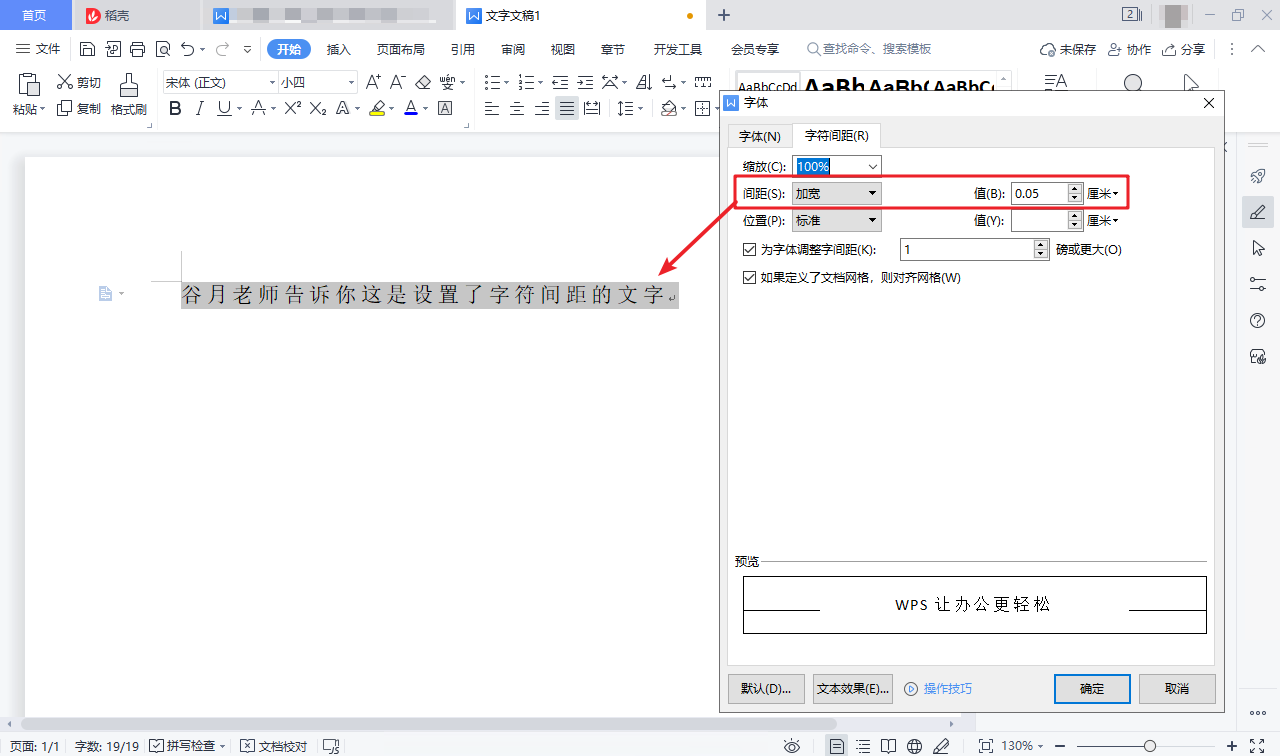
但是题主同学发私信给我说根本不是字符间距。还提供了截图。我找他(她)要了源文件,用 WPS 打开,发现确实如此。
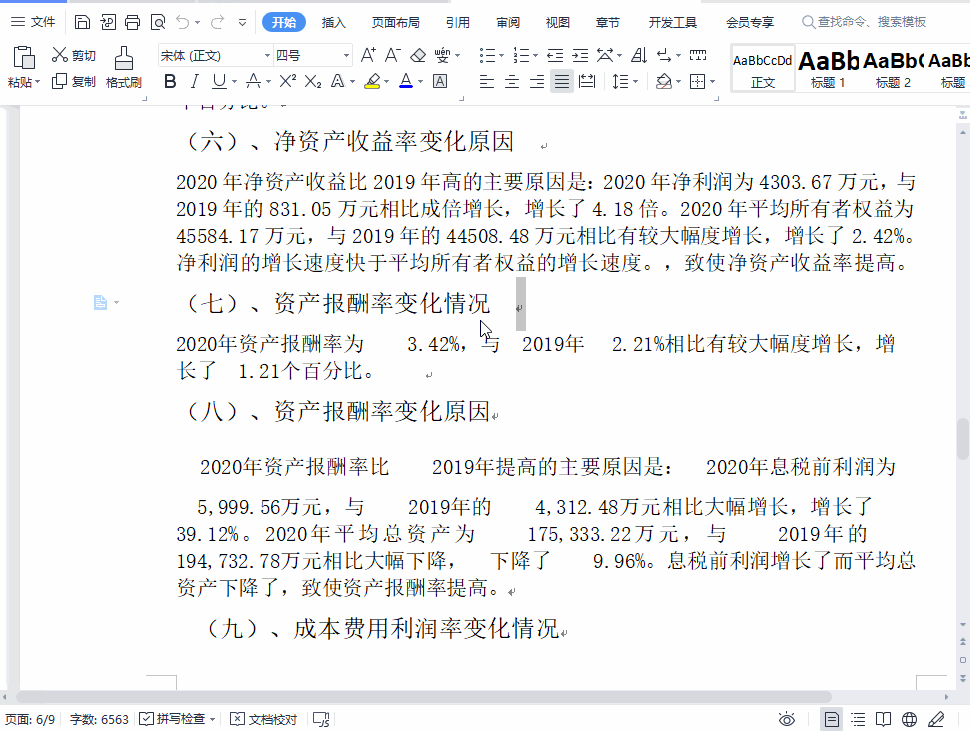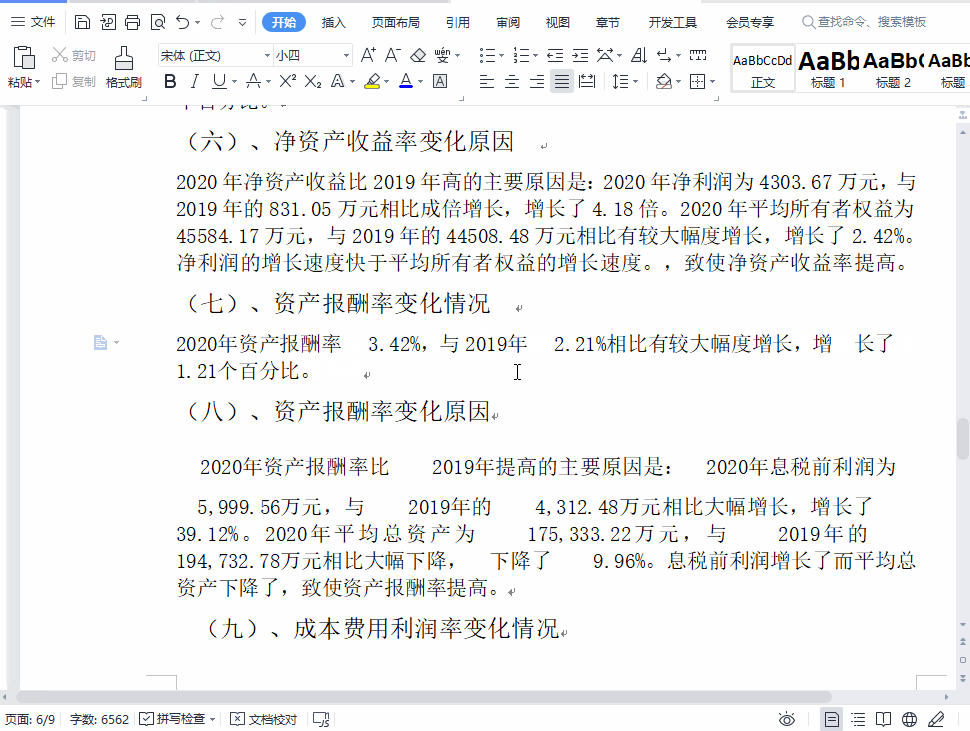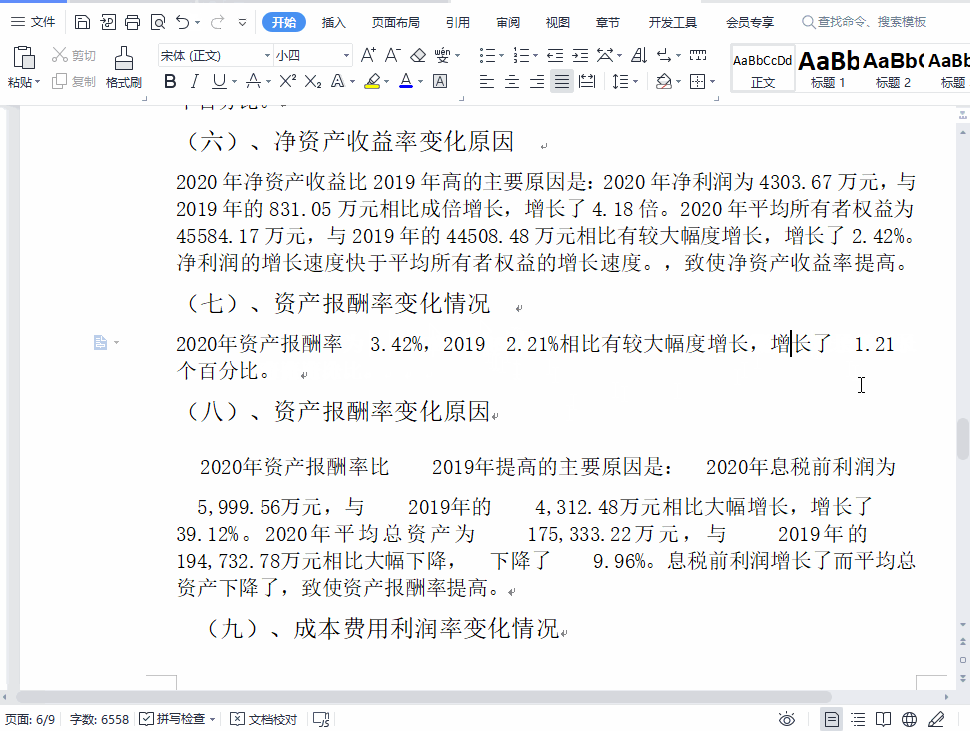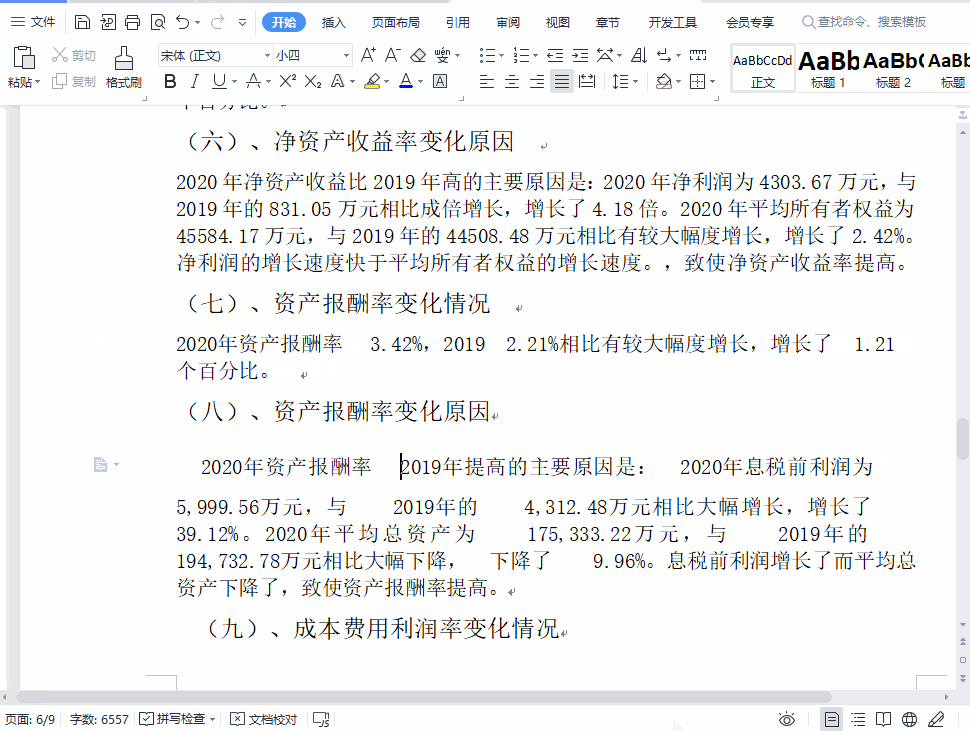
我震惊了,据我对 Unicode 的了解,Unicode 没有收录任何一种能与前面的字符绑定的空格。我甚至私信问题主,是不是他的键盘卡住了……
但它肯定是 Unicode 收录的某个不可见字符,因为 WPS 内部对文档是使用 UTF-8 编码的。
这个空格到底是何方神圣?
我开始分析这个奇葩的空格。
首先要搞清楚它是不是真正的空格。我在 WPS 的“选项”→“视图”→“格式标记”中,打上所有的钩,这样可以让 WPS 显示文档中不可见字符,但是这个空格的显示形式没有任何的变化。这说明 WPS 处理不了这个奇葩的空格。
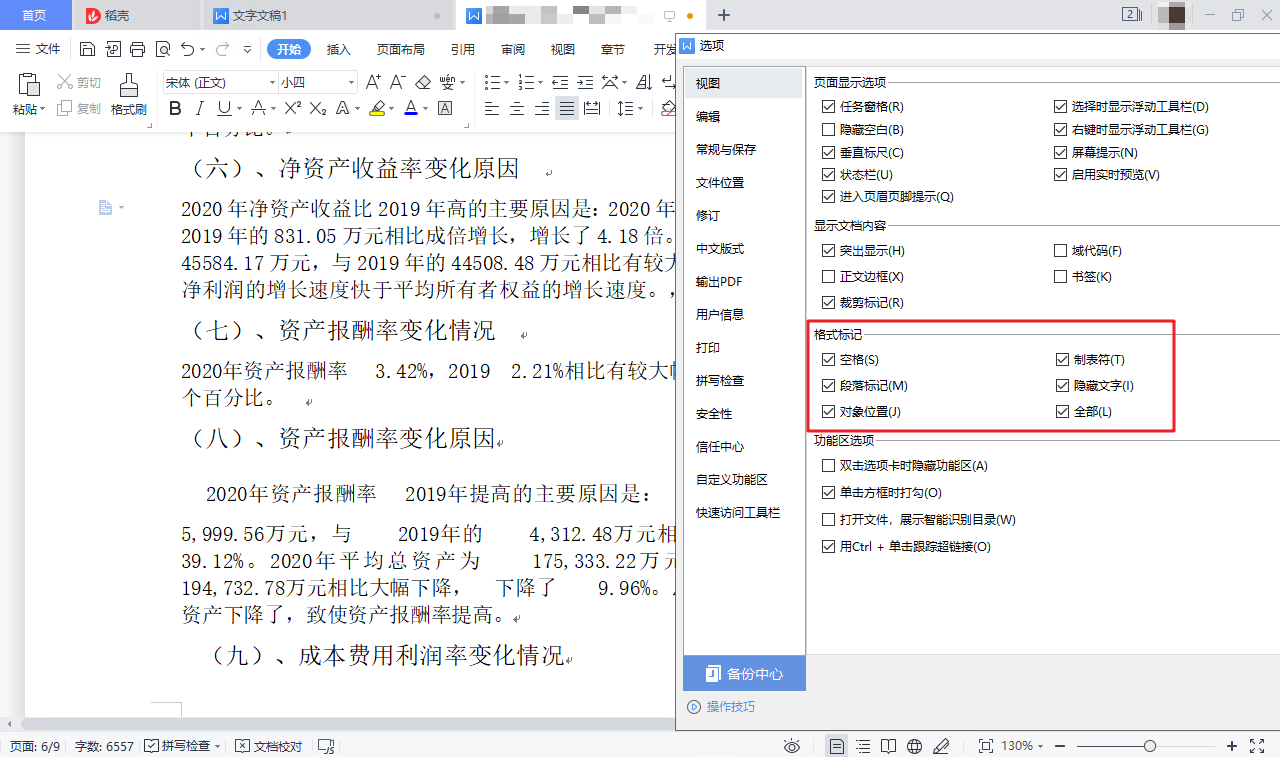
这个空格可以选中,我试着把它复制粘贴到“查找与替换”对话框中,但是发现它不可粘贴,执行粘贴操作以后,我发现是空格前面的那个字被粘贴过去了,我明明只选中了这个空格啊!
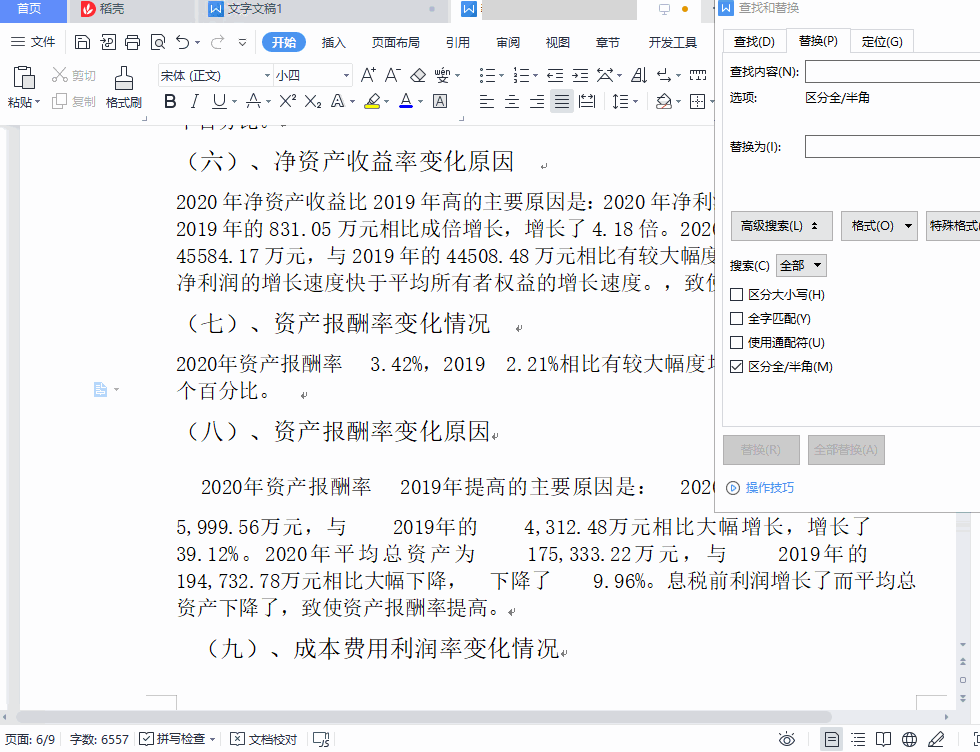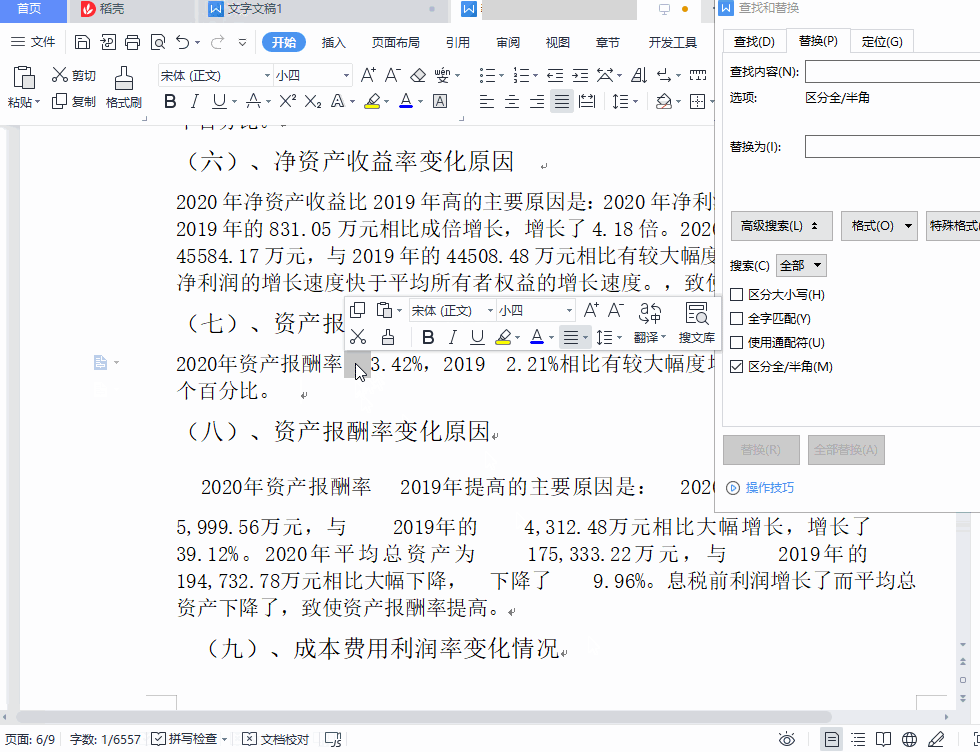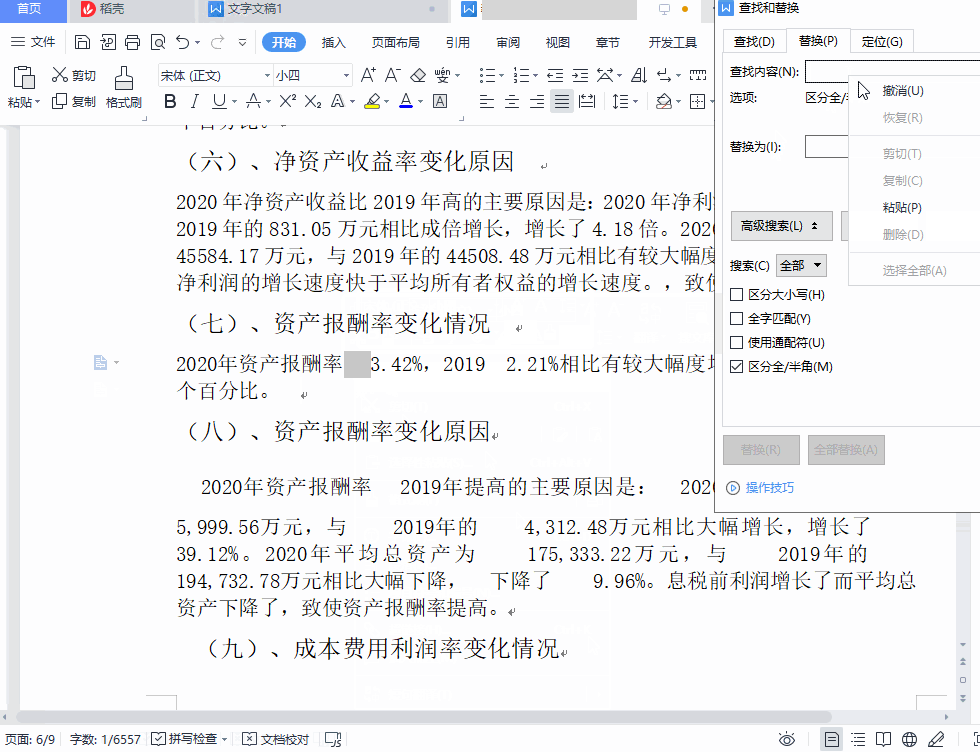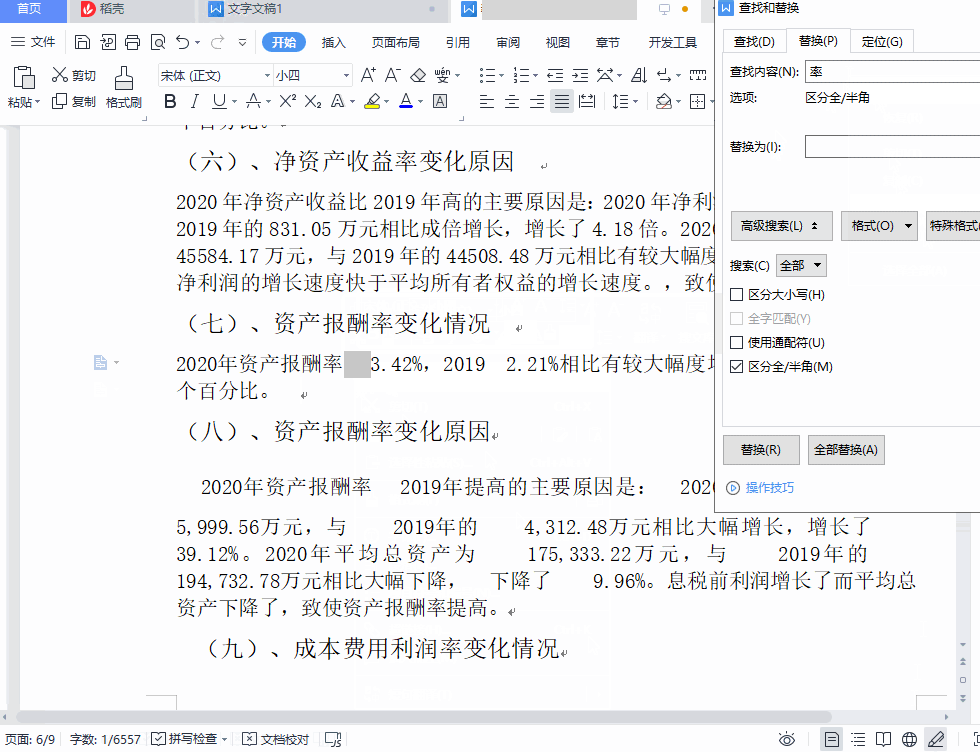
那怎么办呢?只有查看它的内码这一招了。
把含有空格的段落复制到新的文档中,嗯,奇葩的空格还在,仍然会在删除时把它前面的字符一起带走,仍然可以复制但不可粘贴。把新文档另存为文本文件。
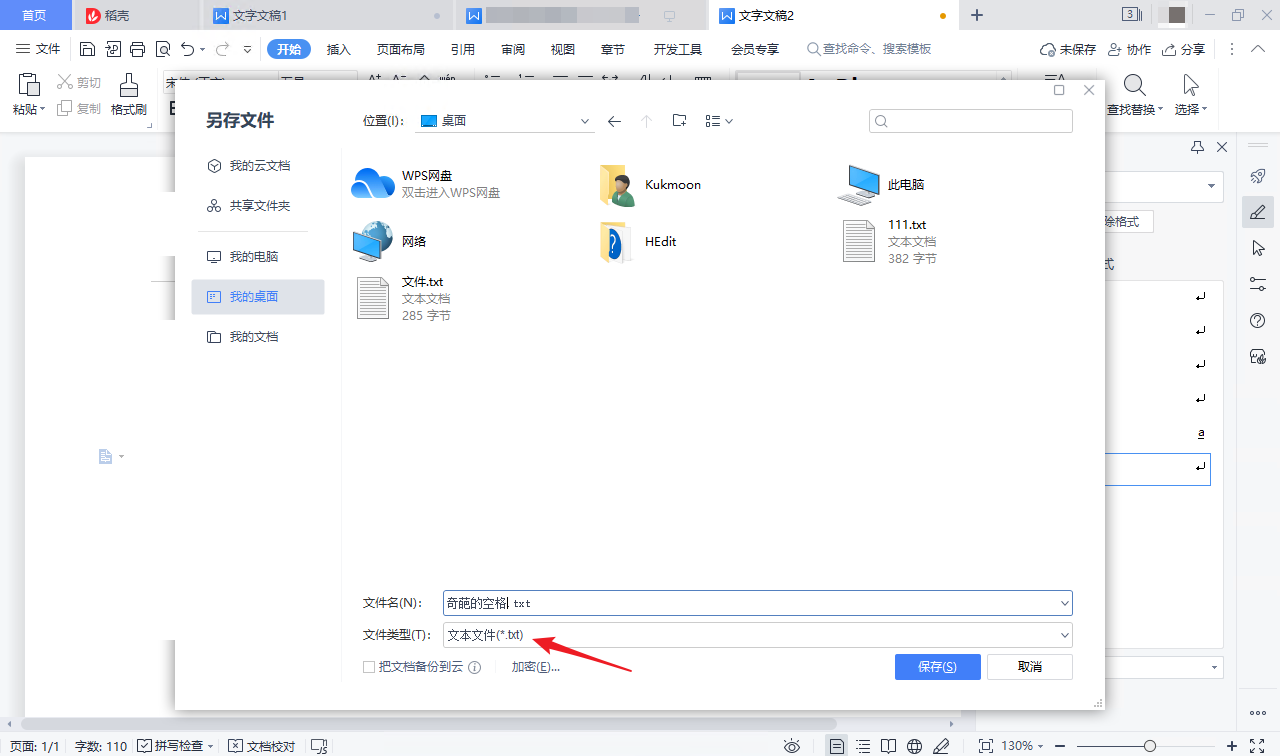
编码类型选择“Unicode UCS-2 Big-Endian”。这种编码格式,每个字符占两个字节,每两个字节的 16 进制编码顺序与 Unicode 编码一致,易于分析。
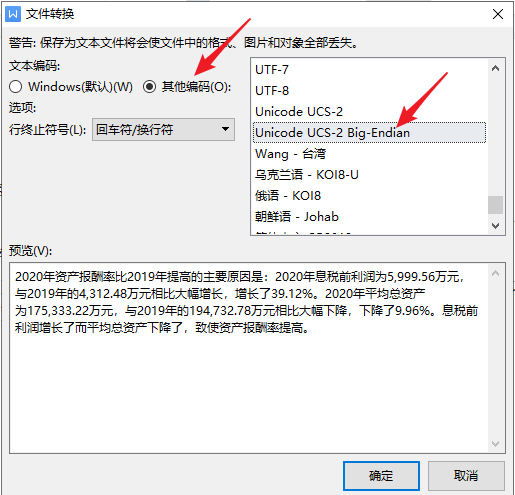
用十六进制编辑器打开,逐个字节分析。原文的“比”和“2”之间有一个奇葩的空格。用 在线 Unicode 转换工具 转换一下,可知“比”的 Unicode 编码为 U+6BD4,“2”的 Unicode 编码是 U+0032。所以在十六进制编辑器中寻找对应的编码,在偏移量为 0x00000019 的行中找到 第 2 和第 3 个字节 0x6B 0xD4 对应“比”,找到第 6 和第 7 个字节 0x00 0x32 对应“2”,那么中间的两个字节 0xFE 0xFF 就对应那个大空格。
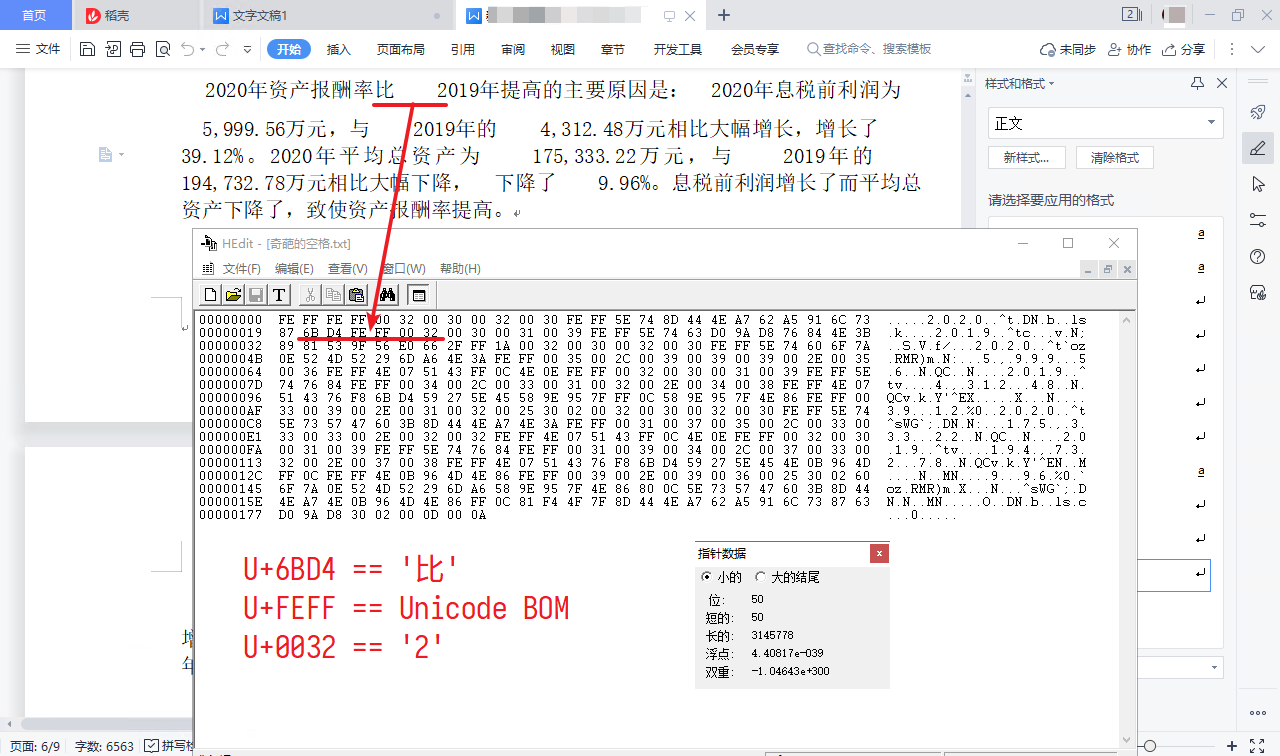
U+FEFF 是 Unicode 的 BOM (byte order mark,字节顺序标记),只能出现在代表文字的数据流的开头。这次在文档中间出现了这个字符,难怪 WPS 不能处理。但是,WPS 让 U+FEFF 与它前面那个字符粘连在一起,删除它就连带着删掉了前面的字符,这绝对是 bug。
如何批量删除这个奇葩的空格
前文已经分析过了,这个奇葩的空格是 Unicode 的 BOM (U+FEFF),WPS 不能粘贴它,所以不能用“查找和替换”批量删除。
不过这也难不倒谷月老师。既然 WPS 原生用 UTF-8 给文档中的文字编码,就说明它具有原生处理 Unicode 字符——包括不可见字符——的能力。用“查找和替换”录制一个宏,把全部的 A 字符替换为空字符,再把宏代码中的 A 字符改成 U+FEFF,不就搞定了吗?
在文档里输入一个原本不存在的字符串组合,例如 AAAAA,然后点击“开发工具”→“录制新宏”,录制一个新宏,给它起个名字,记得保存到当前文档。
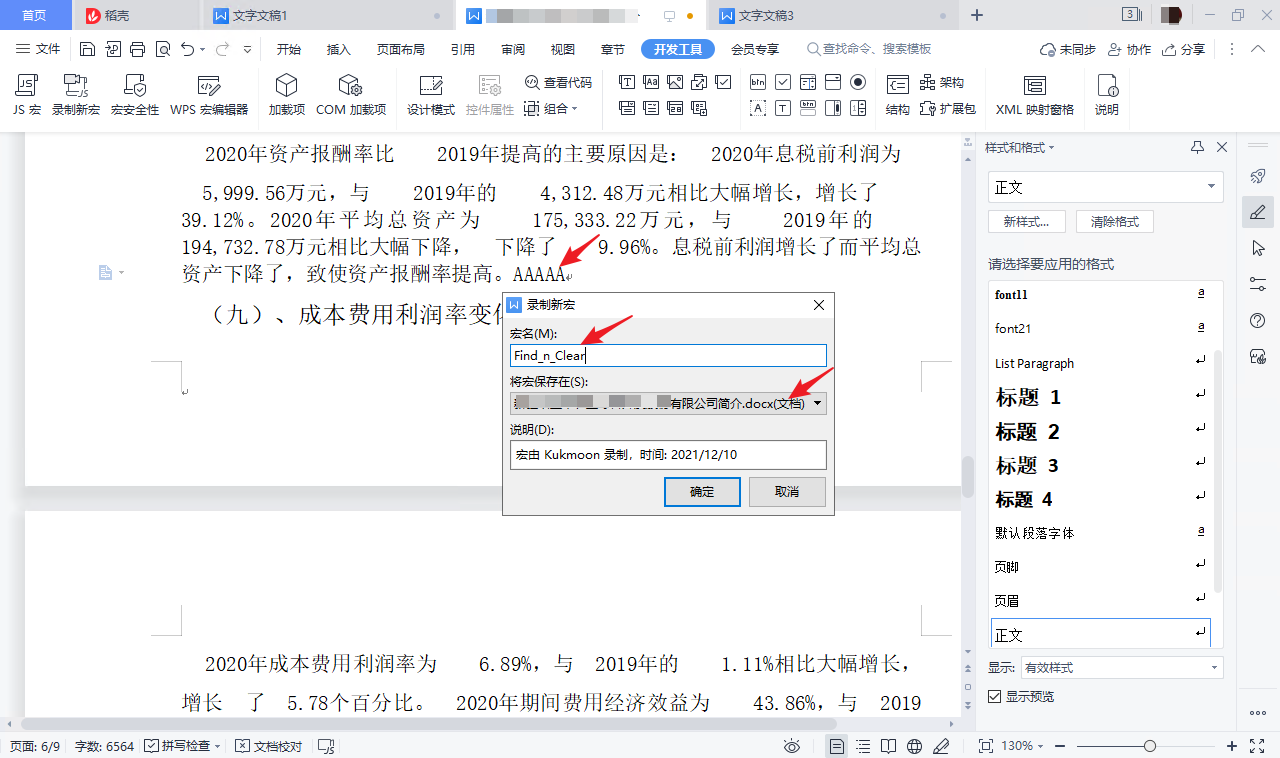
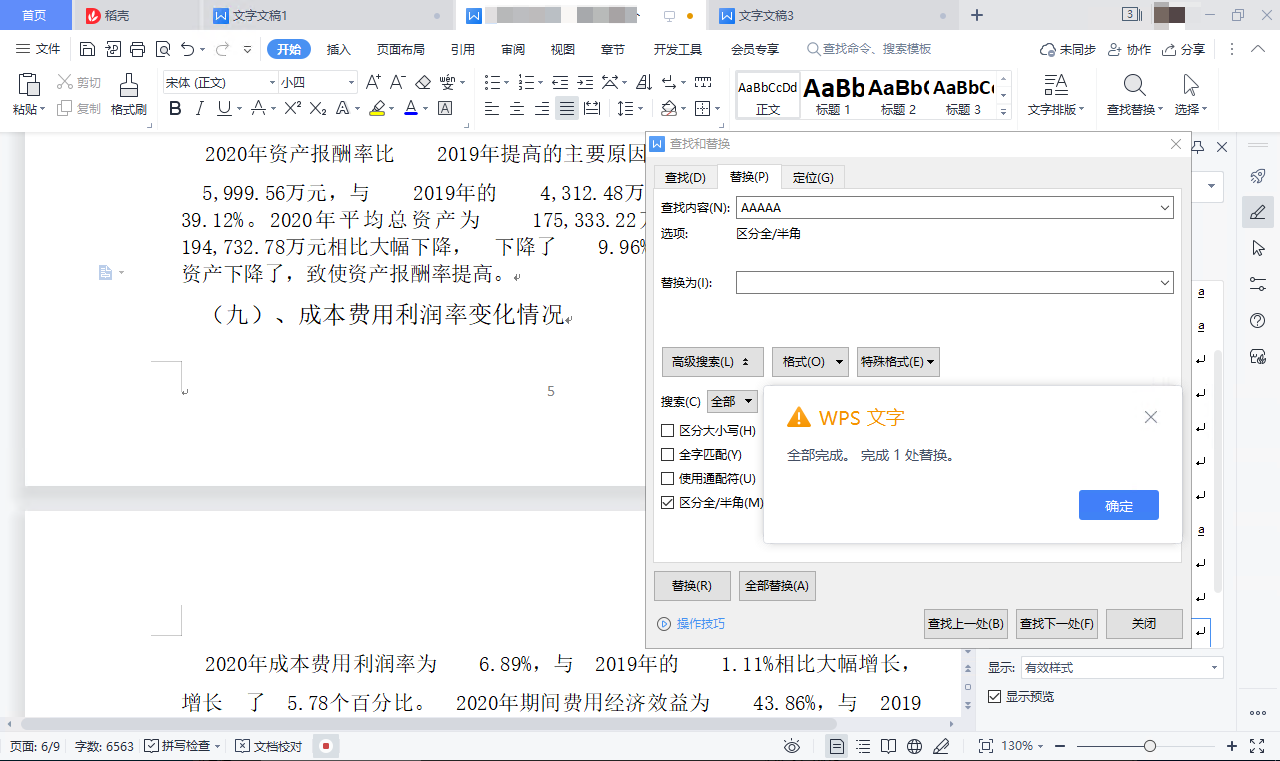
点击“开始”→“查找替换”→“替换”,或者按 Ctrl+H 快捷键,调出“替换”对话框,在“查找内容”中输入 AAAAA,“替换为”框保持空白,点击“全部替换”。然后,WPS 会弹出一个对话框告诉你“已完成 1 处替换”。点击“确定”,再点击“关闭”。
点击“开发工具”→“停止录制”。
点击“开发工具”→“WPS 宏编辑器”,WPS 宏编辑器窗口出现并且直接定位到宏代码(如果没有,就在左侧的“工程”窗口中找到“Project(当前文档的文件名)”→“代码”→“NewMacros”),把代码中 AAAAA 改成 \uFEFF(外层的双引号不要动),然后点击 WPS 宏编辑器窗口工具栏中的“运行”(▶)按钮。这样,原文档中的奇葩的空格就全部被删除了。
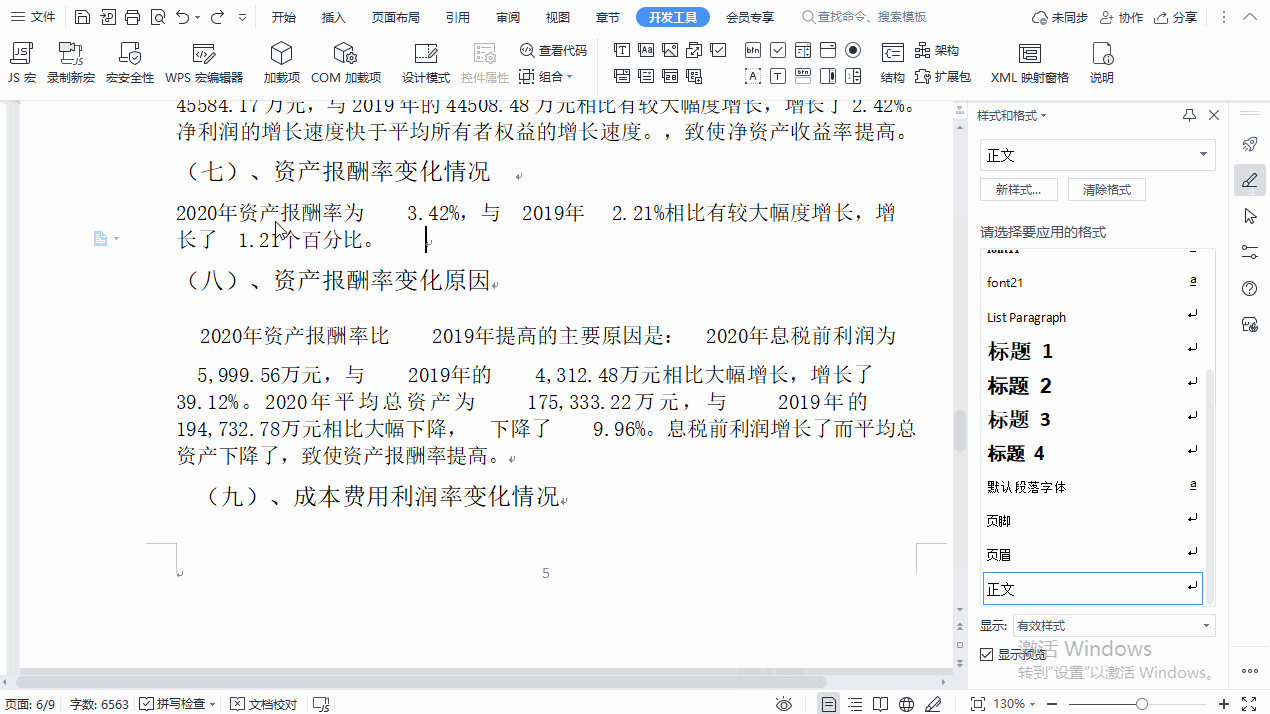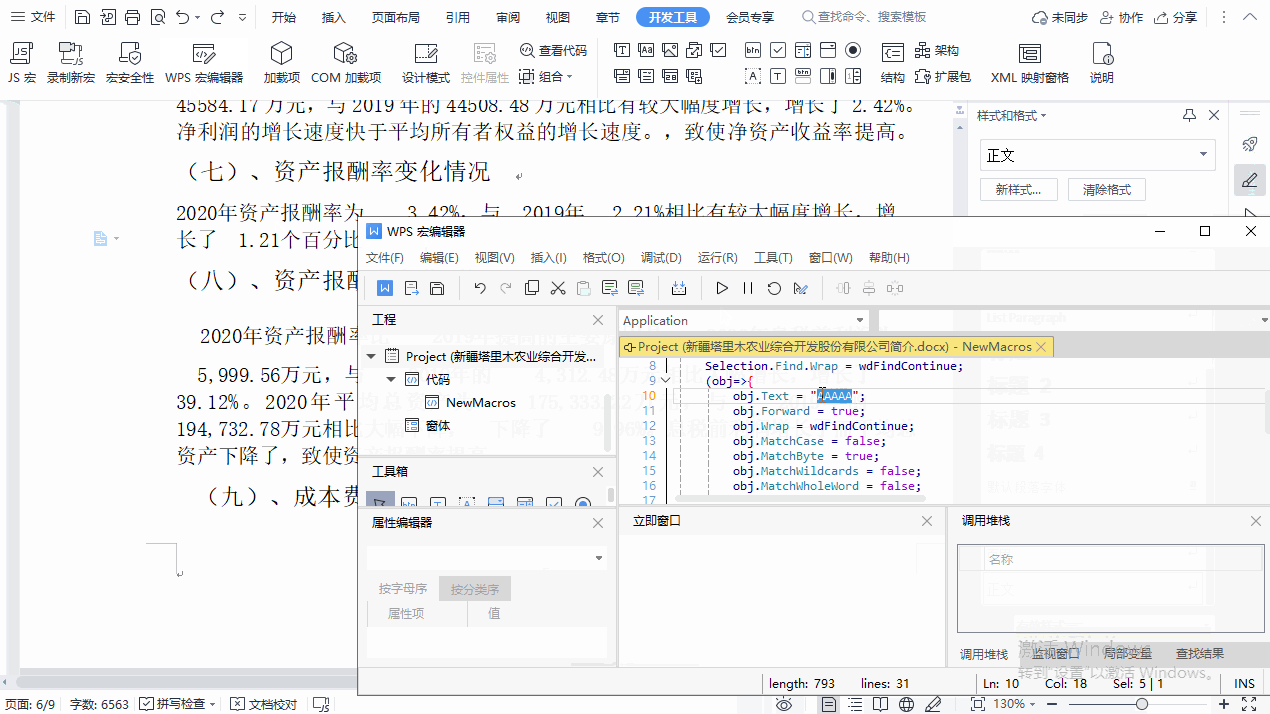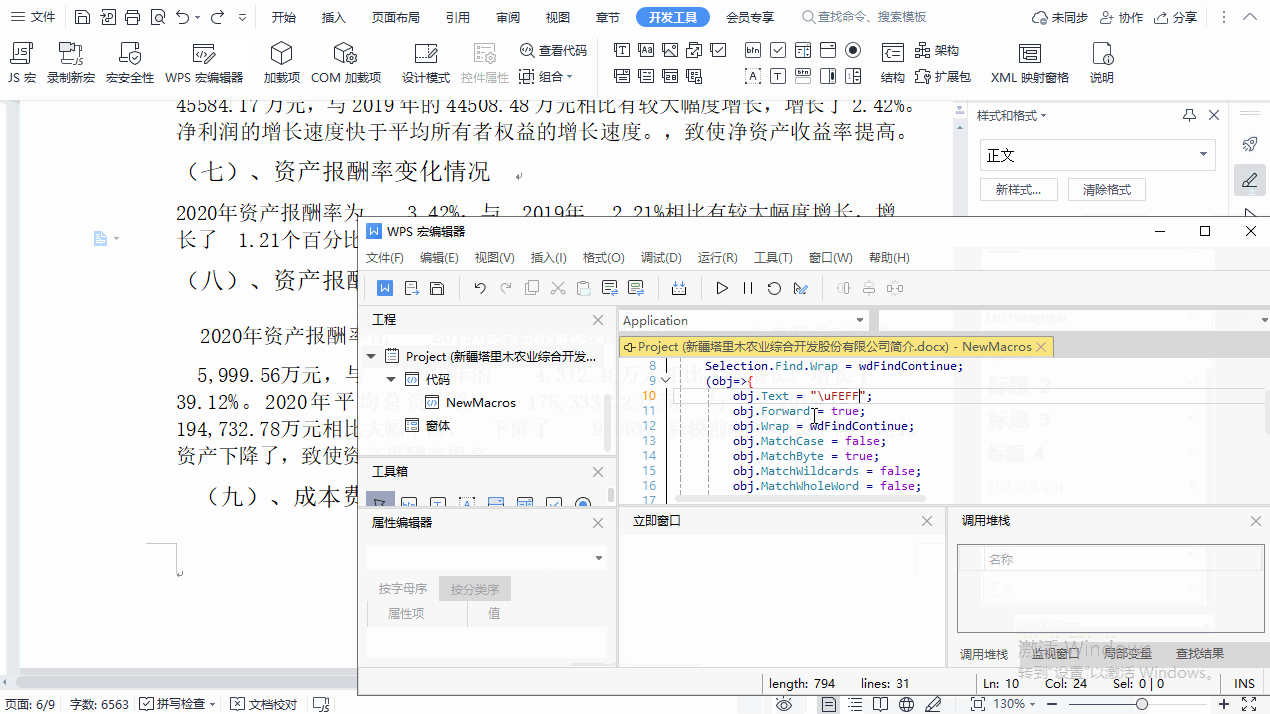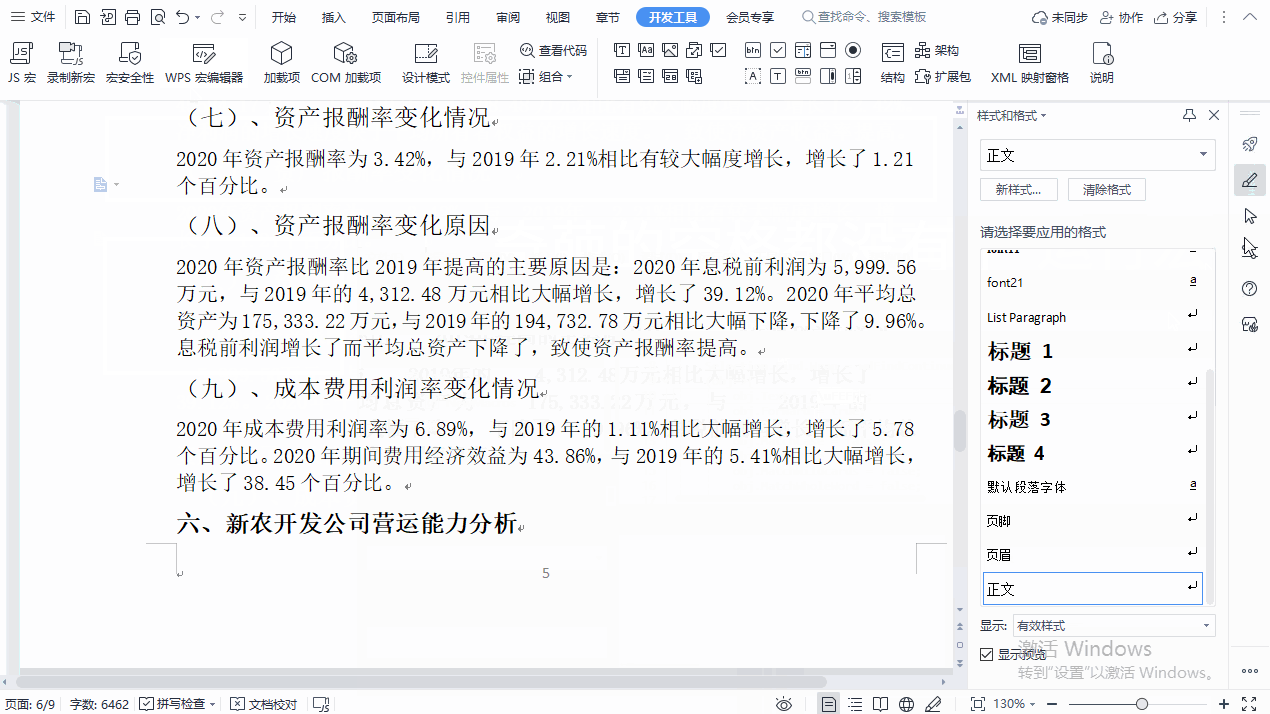
把宏代码贴出来。
1 | |
One More Thing: 微软 Word 能不能处理这个奇葩的空格?
我很好奇,又用 Word 尝试了一下,发现 Word 也无法识别 U+FEFF ,也不能复制粘贴到“查找和替换”对话框中。要批量清除也是要用宏。Word 的宏代码如下。
1 | |
总结
文档中遇到奇怪的不可见字符(invisible characters),应该另存为 UTF-16 Big-Endian 编码格式的文本文档,用十六进制编辑器打开,分析究竟是什么不可见字符,然后用宏代码把它们批量删除掉。
欢迎关注谷月老师的微信公众号

图片版权
头图:Image by Erika Varga from Pixabay

